使用 ICU Message Format 建设国际化
技术点
- ICU Message Format
- @inlang/cli
- next.js
- next-intl
前置知识
国际化(Internationalization,简称 i18n)
国际化指的是设计计算机软件使其能够在不进行工程修改的情况下适应各种语言和地区。理想来讲,国际化只需要执行一次,其也可以作为持续开发过程的一个组成部分。
本地化(localization,简称 l10n)
本地化指的是使用国际化提供的基础设施或者灵活性针对不同的地区提供对应语言的多次过程。
Message(在软件开发过程中)
Message 在软件开发过程中往往用于代指对用户可见的字符串。它们通常携带一些类似于姓名、数字和日期之类的变量元素,作为 UI 的一部分被翻译成多种语言。
什么是 ICU Message Format
语言翻译是一项困难的工作,通常译者需要知晓单个单词所处的上下文,根据语境、主旨为每个翻译目标提供不同的本地化内容,此外,在软件的本地化过程中,还可能会遇到语序颠倒、需要根据上下文选择语句、处理复杂的单复数情况的情景。
ICU Message Format 就是作为解决这些问题的一种国际标准应运而生的。它一般作为一个格式化的类,其规定了语法。目标的格式化字符串称之为“模式”(Pattern)。模式串的语法我们称之为 ICU message syntax。 它可以包含变量占位符,甚至提供富文本的功能,避免将文本拆分成片段和格式化元素进行翻译。
一般地,其占位符使用 {} 符号,视使用的工具支持,也可以进行自定义。
一个常见的 ICU Message Format Pattern,其中,{nickname} 就是占位符:
"Created By @{nickname}" -> message
// 如果使用 next-intl, 那么可以使用如下代码替换占位符
// const t = useTranslations();
// t('message', { nickname: 'Jack'})
// 最后输出的结果就是: Created By @Jack
其中,
{nickname}就是占位符。 只是能够规范占位符,做到替换变量,我们还没有充分的理由使用 ICU Message Format。其真正强大的地方在于其两个强化功能,一是 Plural 模式、二是 Select 模式,这二者组合起来可以使得处理复杂情况下的国际化文本变得简单。此外,不同的工具还为其进行了扩展。 常用到的功能本文涉猎了一部分,其他功能,请参考 Message Format 2.0 或其他库/包的相关文档。
Plural 格式
试想一个具有一定复杂程度的翻译。如果我们想为用户显示一个根据数值提供不同文本的会员横幅,具备以下情况:
如果没有会员天数,那么:
Moss has not share wonderful days with you.如果会员天数为1,那么:
Moss has shared 1 wonderful day with you.如果会员天数为2或更多(用 n 代指),那么:
Moss has shared n wonderful days with you.
一份可能完成上述功能的代码可以是:
function premiumText(count: number) {
if (count === 0) {
return 'Moss has not share wonderful days with you.';
}
if (count === 1) {
return 'Moss has shared 1 wonderful day with you.';
}
return (`Moss has shared ${count} wonderful days with you.`)
}
如果使用 ICU Message Format 完成此项任务,那么就可以编写:
"Moss has {count, plural, =0 {not share}, other {shared #}} wonderful {count, plural, "
"=0 {day} =1 {day} other {days}} with you."
count这里是需要传递的参数,在此条语句中可以用 # 指代。plural这里是启用的格式,常见的有三种格式:plural、select、choice,其中 choice 不鼓励使用,是一个遗留的参数。not share启用格式后,这里的 not share 则是静态文本,交予翻译人员进行翻译#用于快捷使用最前面的变量进行填充,也就是传入的 count
其中,=0 类似的写法被称之为精确匹配。你也可以使用基数格式(Ordinary),也就是类似于 one、two、three、other 这样的量词。此外,在此条语句中可以用 # 使用传入的值。 值得注意的是,还有一种 Select Ordinal 的格式,接受参数与本格式相同,功能也是一致的,以示例说明,就不再赘述:
"You are { POS, selectordinal,"
"one {#st}"
"two {#nd}"
"few {#rd}"
"other {#th}"
" } in the queue."
Plural Offset
如果想生成类似于“我和另外 N 个人一起去吃饭”这样的 Message,提供更好的可读性,那么就可以使用 Plural Offset。 这个功能允许完全确定其复数类别(one、two 这样的类别)之前,从传入的变量中减去对应的值。注意,这个功能对于精确匹配是无效的,精确匹配将会被优先处理。 比如说,这里有一个示例:
"{ count, plural, offset:1"
"=0 {没有人想去吃饭。}"
"=1 {你想去吃饭了。}"
"one {你和一个朋友想一起去吃饭。}"
"other {你约了#个朋友想一起去吃饭}"
"}"
如果传入的 count 小于等于 1,那么就会落入精确匹配,显示“没有人想去吃饭”,或者“你想去吃饭了”。
如果传入的 count 等于2,没有命中精确匹配,那么由于配置了 offset:1,接下来会以 1 来匹配基数词,这里将返回“你和一个朋友想一起去吃饭”。这种 Message 在排除主语或者宾语的量级时是比较方便的。
如果传入的 count 大于2,那么在 other 前的三种情况都没有匹配,那么落入 other,类似于 switch...case 的 default,假设我们传入的是 10 那么就会显示“你约了10个朋友想一起去吃饭”。
Select 格式
假设一个场景,我们需要根据用户的性别选择不同的动词(德语有阴性词阳性词之分)、代词。
如果主语是男性,则:
"He invited him."如果主语是女性,则:
"She invited him."如果用户是非二元性别,则:
"The user invited him."
如果用 ICU Message Format 则可以编写为:
"{gender, "
"male {He}"
"female {She}"
"other {The user}"
"} invited him."
考虑到宾语也可能根据指代人物的性别而变化,实际的情况可能更为复杂。
一个复杂的示例
下面 ICU Message Format 的文档中为我们列出了一个复杂的例子:
"{gender_of_host, select, "
"female {"
"{num_guests, plural, offset:1 "
"=0 {{host} does not give a party.}"
"=1 {{host} invites {guest} to her party.}"
"=2 {{host} invites {guest} and one other person to her party.}"
"other {{host} invites {guest} and # other people to her party.}}}"
"male {"
"{num_guests, plural, offset:1 "
"=0 {{host} does not give a party.}"
"=1 {{host} invites {guest} to his party.}"
"=2 {{host} invites {guest} and one other person to his party.}"
"other {{host} invites {guest} and # other people to his party.}}}"
"other {"
"{num_guests, plural, offset:1 "
"=0 {{host} does not give a party.}"
"=1 {{host} invites {guest} to their party.}"
"=2 {{host} invites {guest} and one other person to their party.}"
"other {{host} invites {guest} and # other people to their party.}}}}"
可以观察到,其中有四个我们需要传入的变量,分别是:gender_of_host、num_guests、host、guest。其含义分别是派对主办人的性别、客人的数量、主办人的名称、某一个客人的名字。
它会首先根据性别 gender_of_host 做一次匹配,然后类似于 switch...case 语句,进入到不同的代码块之中,随后根据 num_guest 再进行匹配。最后,在返回的句子中,对 host 和 guest 进行替换。
如果我们为其传递的数据是:
{
"gender_of_host": "male",
"num_guests": 100,
"host": "Jack",
"guest": "Rose"
}
那么根据上述的规则,我们就可以得到这样一串文本。
"Jack invites Rost and and 100 other people to their party."
富文本支持(扩展)
部分 Message Format 工具,如 next-intl ——支持富文本格式化,举一个在前端开发中使用的例子: 前端代码:
import { useTranslations } from 'next/intl';
function SomeNode() {
const t = useTranslations();
return (
<p>
{
t.rich(
'message_id_1',
{
bold: content => (<b>{content}</b>),
text: '你的文本',
}
)
}
</p>
);
}
文本内容:
{
"message_id_1": "This is a <bold>bold text {text}</bold>"
}
这样,就会渲染出如下内容:
<p>This is a <b>bold text 你的文本</b></p>
Message 的组织形式
如何组织文件
注意,具体翻译文件组织的形式都是自由的,不过一般建议在项目的根目录下使用像是 messages/[locale].json 这样的组织形式。其中 [locale] 是你需要本地化的语言代码,可以遵循 IETF language tag 的规范。类似于 en.json 或者 zh-CN.json 。
比如:
├── .next/
├── .vscode/
├── messages/
│ ├── en.json
│ ├── zh-CN.json
│ ├── zh-TW.json
│ └── id.json
├── next.config.js
├── package.json
├── pnpm-lock.yaml
├── README.md
└── tsconfig.json
当然,你也可以根据需要将不同的语言整合在一起,使用一个较大的 Message Catalog,或是按照模块进行更细模块的拆分。
在使用时,根据需求,也可以自定义各个 Message 的整合方式,比如阿拉伯语使用英语作为兜底,合并两侧的 JSON 数据;或者根据使用的模块组合在 SSR 时进行 Message 的部分加载等。
而对于文件内的 Message 如何组织,这里有两种方案。
按模块或组件划分的 ID
一种策略是,使用带有明确意义的字符串,借助分割符号,或者嵌套结构,提供按组件拆分的 Message Catalog。
{
"HomePage": {
"Title": "Hello World",
"Description": "Paragraph"
},
"HomePage_Title": "Hello World",
"HomePage_Description": "Paragraph"
}
这种方案的好处在于,根据模块划分的 Message 一眼就能知道具体在哪个模块使用,从人类可读性来说是非常棒的。但是也存在对应的缺点:
- 绑定模块,模块变更或者复用重复文本时,ID 的含义陷入比较尴尬的田地;
- 易发生频繁的 ID 变更,难以追踪 Message 的历史变化;
- 可能会发生一些关于 ID 命名的无效讨论。
使用扁平的人类可读随机 ID
https://inlang.com/documentation/concept/message#idhuman-readable https://github.com/opral/monorepo/issues/1892
另一种策略是,使用随机的人类可读的 ID。这种方案好处在于:
- 较好地避免了关于 ID 命名的讨论;
- 提供一个没有必要变化的 ID 用于追踪变更历史;
- 有现成工具快速生成对应的 ID。
刚好与前一个方案相反,它无法直接知道 Message 在哪个模块被使用,只能够通过工具进行检索。
语言标志与应用的结合
一般地,语言标志会使用国家标签或者语言标签。其中语言标签应该根据 IETF language tag 规范确定。比如说,标签 en 指代英语,它作为子标签跟随子标签 US, en-US 指代美式英语。两个子标签之间以 - 连接,每个子标签仅由基本的拉丁字母和数字组合。一般祖先标签后面最多跟随三个子标签,可以使用其他规范中的区域子标签。
常见的策略有三种,其中前两种是 Web 经常使用的。
作为子目录的语言标志
比如:example.com/zh-CN、example.com/en 这种做法既搜索引擎较为友好,实现的消耗也比较低。缺点是更适合用于单一主机,如果想要协同多个主机,需要比较复杂的规则处理。一般来说,这种做法是中小型网站权限之后的推荐做法。
作为域名一部分的语言标志
作为顶级域名的国家/地区标签 例如:example.de 这种方案适用于网站的服务与具体的地域关联,不仅仅是语言上的变化。注意,这里的国家/地区标签很有可能和语言标签不是一致的。 用户一般认为,这种带有国家标签的网站更具有辨识度,而且会根据顶级域名对应的国家/地区进行服务上的变化。 此方案的成本较高,需要购买多个域名并针对每个域名做相应的配置和维护。
作为子域名的语言标签
例如:en.example.com 这种方案的网站区分度比较高,但用户无法确定子域名中到底是语言标签还是地域名称,辨识度没有那么清晰。这种方案也易于将不同语言的域名转发到不同的主机之中。
作为内置变量的语言标签
放在内存或其他存储中的语言标签 这种方案适用于单语言的应用,或者不暴露 URI 的应用,以及客户端应用。一般,Web 中将其存放到 WebStorage、Cookie 之中,App 可能存放到本地数据库中,待到使用时再进行读取。 这就是完全不需要进行 SEO 的场景经常使用的方案了。
放在查询参数中的语言标签
例如:example.com?lang=de 这种方案不推荐,也对搜索引擎不友好,多参数时更难以让用户区分网站的语言或地理位置。
自动确定语言标签
例如:example.com Accept-Language: en-US 需要注意的是,由于搜索引擎爬虫总是不一定来自不同的地域,因此 Accept-Language 请求头(或者类似的技术)不一定会不同,因此很难这种用法里很难覆盖多语言的 SEO。同时,用户也难以查看某一页面的所有版本。
配套工具
针对于不同编程语言或框架,有不同的包和工具提供 ICU Message Format 的格式化。
比如说,对于 next.js 就可以使用 [next-intl](https://next-intl-docs.vercel.app/),Java 可以使用 MessageFormat 类(com.ibm.icu.text.*),C 和 C++ 也有类似的类可以使用。
next-intl
https://next-intl-docs.vercel.app/
next-intl 是 next.js 进行国际化的一个包。 假设一个翻译的 JSON 是这样的:
{
"title": "Hello world!"
}
通过 next-intl,我们可以在服务端生成 metadata 时这样读取:
export async function generateMetadata(
{ params: { locale } }: { params: { locale: string } }
) {
const t = await getTranslations({ locale });
return {
title: t('title'),
};
}
或者在普通的组件中这样读取这样:
export default function Page() {
const t = useTranslations();
return (
<h2>{t('title')}</h2>
);
}
此外,如果需要根据组件进行划分,或是根据页面进行划分,可以使用如下的形式:
{
"HomePage": {
"title": "Hello world!"
}
}
export async function generateMetadata(
{ params: { locale } }: { params: { locale: string } }
) {
const t = await getTranslations({ locale });
// 或者 const t = await getTranslations({ locale, namespace: 'HomePage' });
return {
title: t('HomePage.title'),
};
}
export default function Page() {
const t = useTranslations();
// 或者 const t = useTranslations('HomePage');
return (
<h2>{t('HomePage.title')}</h2>
);
}
此外,针对于我们上一节提到的几种语言标志结合模式,Next-Intl 的文章都有给出使用的示例。
Inlang 工具
围绕 ICU Message 的工作流简化,inlang 提供的工具非常好用。如果需要其他框架的工具或配置,可以前往其官网查看。
Inlang 项目配置
通过在项目的根目录下放置一个目录,提供一个 settings.json,可以快速配置 Inlang 相关工具。完整的配置步骤见这里。
 比如一个实际使用的 settings.json 是这样的内容。这是根据这篇文章进行配置的。
比如一个实际使用的 settings.json 是这样的内容。这是根据这篇文章进行配置的。
{
"$schema": "https://inlang.com/schema/project-settings",
"sourceLanguageTag": "en",
"languageTags": [
"en",
"ar",
"bn",
"cs",
"da",
"de",
"el",
"es",
"fi",
"fil",
"fr",
"hi",
"id",
"it",
"ja",
"ko",
"ms",
"pt",
"ru",
"sv",
"th",
"tr",
"vi",
"zh-CN",
"zh-TW",
"ta",
"pl",
"he"
],
"modules": [
"https://cdn.jsdelivr.net/npm/@inlang/plugin-next-intl@latest/dist/index.js"
],
"plugin.inlang.nextIntl": {
"pathPattern": "./messages/{languageTag}.json"
}
}
注意:这里只是针对地配置了 inlang 相关工具的配置,如果需要做国际化框架的搭建,你可能需要根据自己所使用的框架或者语言选择国际化的方案。比如说,App Router 没有正确地处理 middleware 的匹配,是没有办法到对应本地化的地址的。具体如何配置,还要取决于使用到的框架和包。
Inlang Sherlock
一部分是 Inlang Sherlock,它是一个 VSCode 插件,用于简化翻译文本的提取。
 在 VSCode 市场中搜索 Sherlock 也可以进行安装,也可以通过这里链接内的按钮安装。
一个简单的示例,如果我们有三份字符串:
在 VSCode 市场中搜索 Sherlock 也可以进行安装,也可以通过这里链接内的按钮安装。
一个简单的示例,如果我们有三份字符串:
"This is a text"
`This is a text`
'this is a text'
它可以为你自动提取字符串,放到你配置的默认语言文件里(如 messages/en.json),返回规范的函数调用。最后这些字符串都可以转换为以下几种(仅举例几种)调用。
{t('message_id')}
t('message_id')
m.message_id()
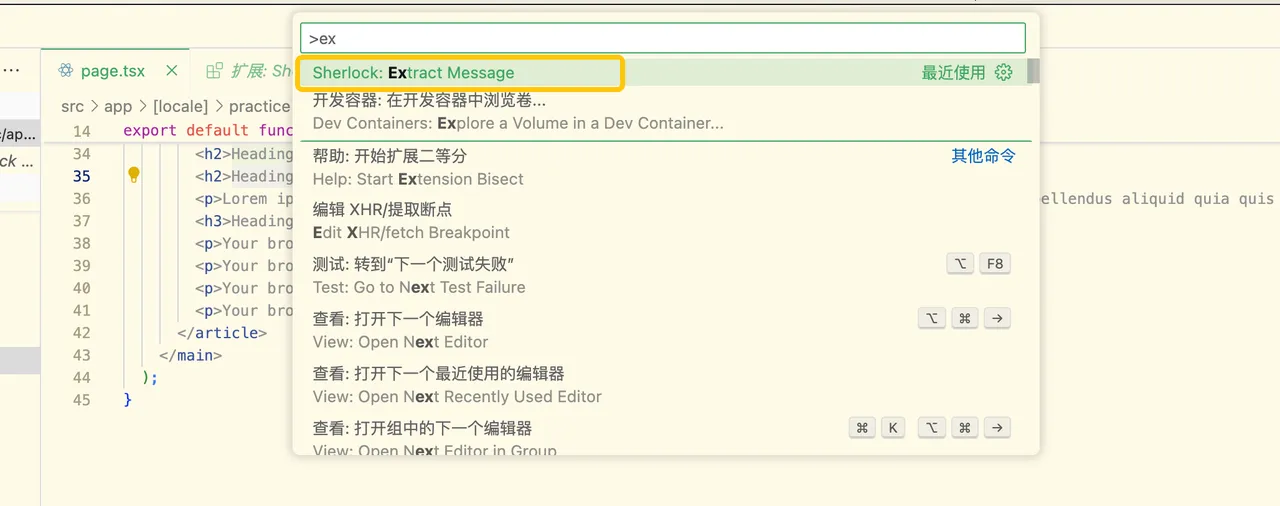
假设你已经完成了配置,而这仅需要几步简单的操作:
如果你是 Mac OS,那么 Cmd + Shift + P(或者,查看 -> 命令面板),输入 Extract(或者 Extract 自动补全),选择 Sherlock 的指令。
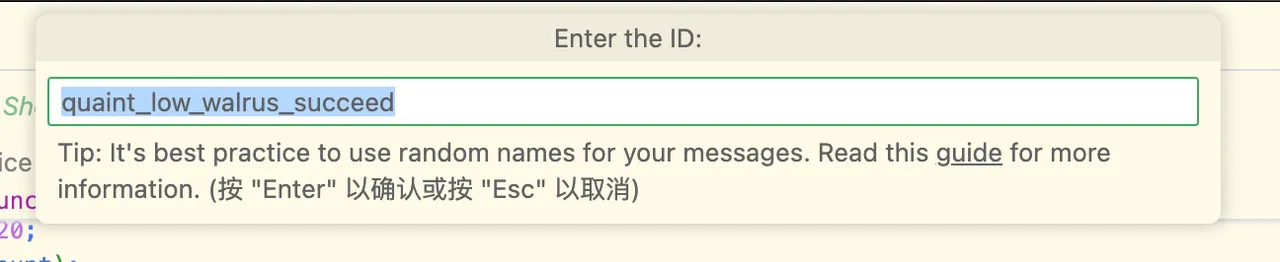
 输入 ID,它会为你自动生成一个人类可读的随机ID。你也可以通过 HomePage.title 指定嵌套的文本。按下回车,它就会自动将提取的文本 + ID 插入你预先配置好的默认语言的 Message Catalog 中。
输入 ID,它会为你自动生成一个人类可读的随机ID。你也可以通过 HomePage.title 指定嵌套的文本。按下回车,它就会自动将提取的文本 + ID 插入你预先配置好的默认语言的 Message Catalog 中。
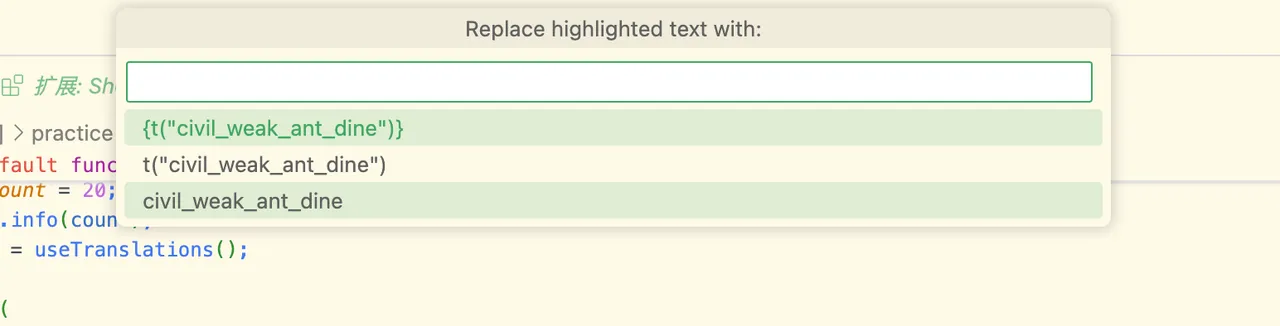

接下来,你只要像这样使用就可以了:
export default function Page() {
const t = useTranslations();
return (
<h2>{t('civil_weak_ant_dine')}</h2>
);
}
Inlang CLI
另外一个 Inlang 为我们提供的工具是 @inlang/cli,可以通过如下命令进行使用: npx @inlang/cli [command] 你也可以通过安装为 devDependences 进行使用。 npm install -D @inlang/cli 最常用的命令有两个: 验证当前 inlang 是否正确配置 这个 validate 功能可以配合 inlang 的 lint 规则一起使用。
npx @inlang/cli validate --project ./path/to/{project-name}.inlang
机器翻译
常用的指令是:
npx @inlang/cli machine translate --project ./path/to/{project-name}.inlang --targetLanguageTags [targets...]
比如一个真实世界的示例,输入后 Terminal 确定进行翻译即可自动生成机器翻译。
npx @inlang/cli machine translate --project project.inlang
这样,就可以快速生成其他语言文本的翻译。

完成工作流
至此,我们涉及了国际化工作流的几个部分:
- 确定 Message 组织形式;
- 确定 Message 的渲染方案;
- 确定语言标签如何与应用结合;
- 半自动化 Message 提取和翻译。
实际上,如果我们对翻译的质量不甚精确,或者不需要研发之外的协作,基本上一个国际化的工作流就已经结束了,自己检查一下 VSCode 中的翻译文本即可。
最后一公里
但如果作为规范化的产品,那么需要我们补足这国际化的最后一公里——与翻译人员(产品经理/专业翻译)协作。 我们可以接入一个校对平台,将初翻的版本同步给翻译者或校对者。待到完成翻译后,再同步将翻译的文本接入回项目。
一个较为合理的国际化 Git 工作流如下:
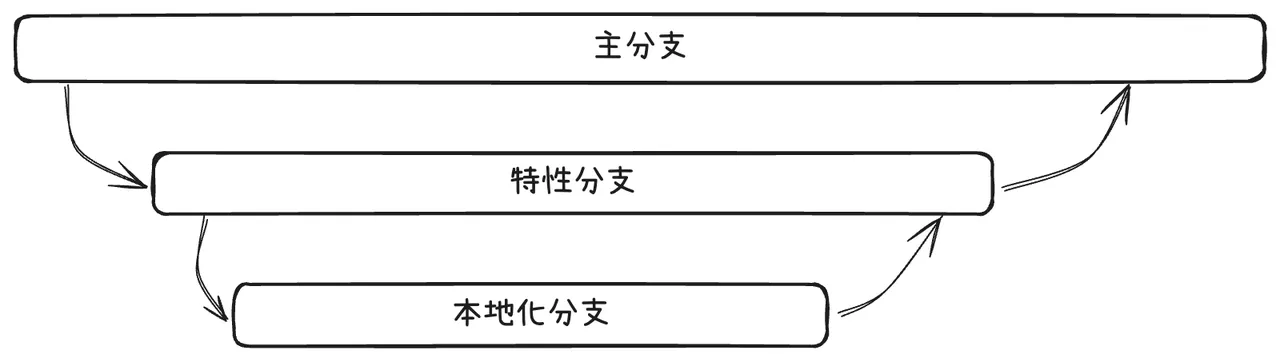
我们基于特性分支,完成 Message 提取后,新建本地化分支,通过 Webhook 或其他方式,同步给对应的翻译平台或者校对平台。等到翻译完毕后,重新整合回特性分支,待到测试完成后合并回主分支。Next-Intl 的文档中也有相应的部分。
翻译三方平台
我们可以选择使用第三方翻译平台,CrowdIn、Flink、Weblate。 CrowdIn:比较好用的第三方平台,具有翻译字典、完整的翻译校对流程等,私有项目需要付费。 Flink:功能比较简单,仅适用于 Github 项目。 Weblate:可以免费自 Host,功能也比较强大。 本人只用过前两个三方平台,CrowdIn 在翻译开源项目时是非常强大的。